Kubernetes Part 2: Architecture
In this series of articles, we’ll take a deep dive into the world of container orchestration and start playing with Kubernetes hands-on. In this article, we’ll take a look at the Kubernetes architecture and learn more about how it’s laid out.
Nodes & Pods
A node can be a physical machine, a virtual machine, or a virtual machine in the cloud. Inside a node, we have pods, and inside a pods we have containers, and there can be multiple containers in the pod. The worker node hosts the pods that are the components of the application. The master node manages the worker nodes and the pods inside the cluster.
- Useful information: As of the latest version of Kubernetes, a cluster can have up to 5,000 nodes. More specifically, Kubernetes supports no more than 5,000 nodes, no morethan 150,000 total pods, and no more than 300,000 total containers.
Master & Worker Nodes
In Kubernetes, we have masters and worker nodes. Together they form a cluster. The master node manages the work nodes within the cluster. When you deploy Kubernetes, you get cluster, which is made up of nodes. A cluster has at least one master node and one worker node.
Master node is responsible for managing the cluster and monitors nodes and pods in a cluster. When a node fails, it moves the workload of the failed node to another worker node. There are four components of the master node:
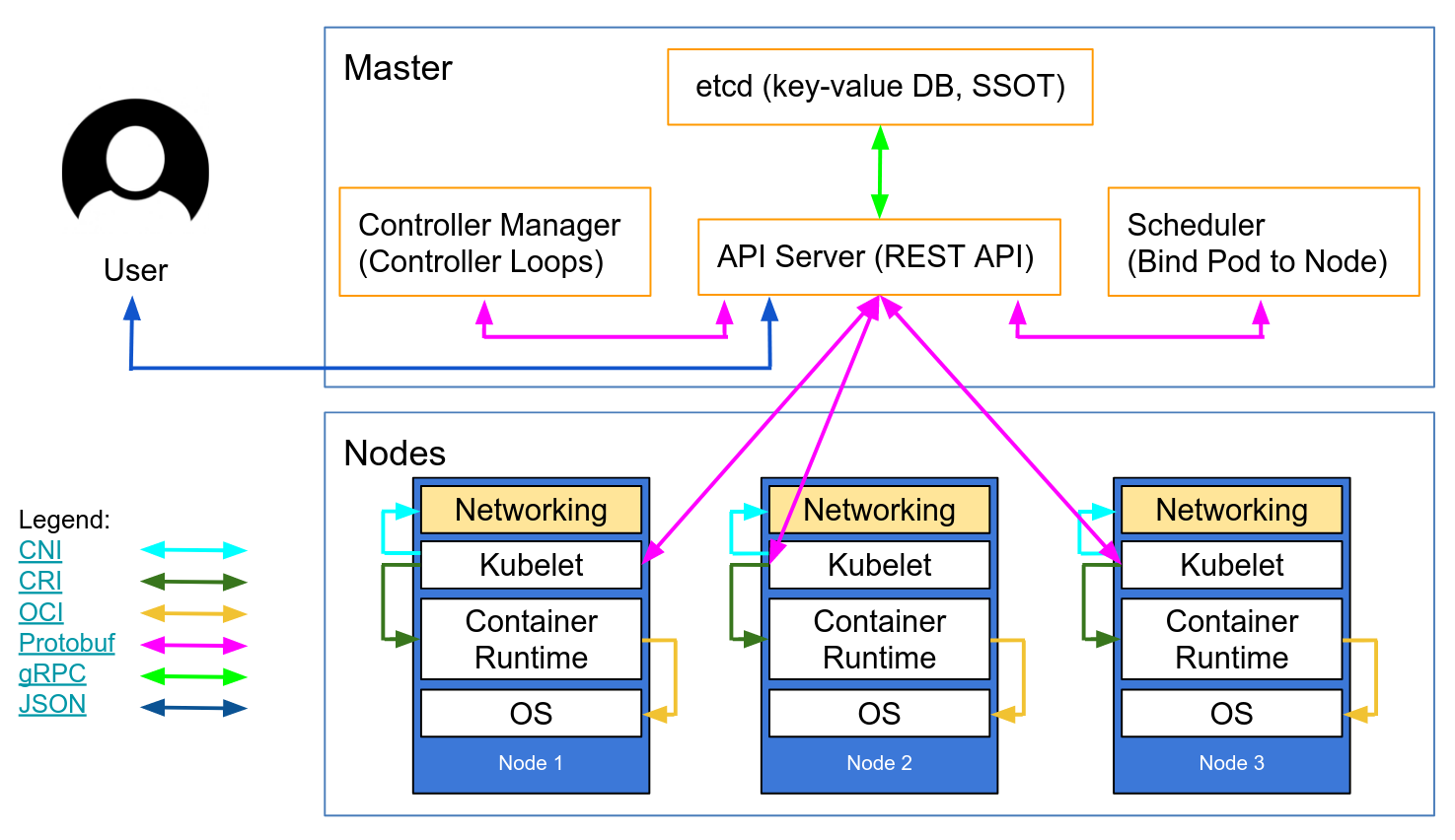
API Server
The API Server is responsible for all communications (JSON over HTTP API). It exposes some APIs for almost every operation, and a user can interact with these APIs from a UI or from the kubectl command line tool, which is written in the Go programming language.
Scheduler
Schedules pods on nodes. The Scheduler is a component on the master that watches newly-created pods that have no node assigned, and selects a node for them to run on. It can read the hardware configuration from the configuration file in etcd and schedules the pods on nodes accordingly. The Scheduler obtains all of this config information from etcd datastore through the API Server and combines that with resource usage data for each worker in the cluster.
Controller Manager
This component runs and monitors controllers. There are two types of Control Managers: kube-controller-manager and cloud-controller-manager. The kube-controller-manager runs controllers that act when nodes become unavailable to ensure pod counts are as expected. It also creates endpoints, service accounts, and API access tokens. Logically, each controller is a separate process, but to reduce complexity, they are all compiled into a single binary and run in a single process.
Let’s go a litte deeper and see all of the kube-controller-manager’s child components. The Node Controller is responsible for noticing and responding when nodes go down. The Replication Controller is responsible for maintaining the correct number of pods for every Replication Controller object in the system. The Endpoints Controller populates the Endpoints object, and oins services and pods. The Service Account and Token Controllers create accounts and API access tokens for new namespaces.
All of these controllers watch continuously to compare the cluster’s desired state (from the hardware configuration) to its current state (obtained from etcd datastore via the API Server). If there is a mismatch, then it will take corrective action in the cluster until its current state matches the desired state.
The cloud-controller-manager runs controllers responsible to interact with the underlying infrastructure of a cloud provider when nodes become unavailable, to manage storage volumes when provided by a cloud service, and to manage load balancing and routing. It runs the following controllers Node Controller, Router Controller, Service Controller, and the Volume Controller. The Node Controller checks the cloud provider to determine if a node has been deleted in the cloud after it stops responding. The Route Controller sets up routes in the underlying cloud infrastructure. The Service Controller creates, updates, and deletes cloud provider load balancers. Finally, the Volume Controller creates, attaches, and mounts volumes and interacts with the cloud provider to orchestrate volumes.
Etcd
This component is an open-sourced, distributed key-value database that acts as a datastore.
The worker node can be any physical or virtual machine where containers are depoyed. Every node in a Kubernetes cluster must run a container runtime like Docker. There are three components in each node: kubelet, kube-proxy, and the container runtime. Node components run on every node, maintaining running pods, and providing the Kubernetes runtime environment.
kubelet
Is an agent running on each node that communicates with components from the master node. It makes sure that containers are running in a pod. The kubelet takes a set of PodSpecs taht are provided through various mechanisms and ensures that the containers described in those PodSpecs are running and health. If there are any issues, kubelet tries to restart the pods. kubelet does not manage containers not created via Kubernetes.
kube-proxy
Is a network agent that is responsible for maintaining network configuration and rules, which exposes services to the outside world.
Container runtime
Is the software that is responsible for running containers. The most common one is Docker, but there are others such as Containerd, Cri-O, etc… Kubernetes does not have the capability to directly handle containers. So in order to run and manage a container’s lifecycle, Kubernetes requires a container runtime on the node where a pod and its containers are to be scheduled.